Securing AI Agents: Why Posture Now Matters More Than Ever
The rise of AI Agents is one of the most significant shifts we’re seeing in technology right now. Unlike traditional applications or cloud workloads, AI agents are not passive systems. They reason. They make decisions. They call tools. They interact with other systems, and sometimes even with other agents.
That autonomy creates massive opportunity.
It also introduces a completely new risk profile.
And as Microsoft highlights, the barrier to creating AI agents is low. Teams can build and deploy them quickly, often without fully understanding the security implications. That changes the security equation entirely.
This is where AI agent posture becomes critical.
The goal is not to slow innovation or block adoption. It’s to ensure AI agents are deployed securely by design, with visibility and control from the start.
What AI Agent Posture Really Means
According to Microsoft, strong AI security posture begins with comprehensive visibility across all AI assets. But visibility alone isn’t enough.
It also requires contextual understanding:
- What can this agent actually do?
- What data is it connected to?
- What tools can it invoke?
- What identities does it operate under?
- What risks does it introduce?
- How should those risks be prioritized and mitigated?
In other words, AI agent posture is about understanding capability plus exposure.
And that combination is what makes this uniquely complex.
The Unique Security Challenges of AI Agents
Microsoft emphasizes that the attack surface of an AI agent is inherently broad.
Agents are composed of multiple interconnected layers:
- Models
- Platforms
- Tools
- Knowledge sources
- Guardrails
- Identities
- External integrations
Each of these layers introduces its own attack vector.
Threats can include:
- Prompt-based attacks
- Poisoning of grounding data
- Abuse of connected tools
- Manipulation of coordinating agents
Securing AI agents, therefore, cannot be handled as a single control problem. It requires a holistic, layered approach.
Overlooking even one component in this ecosystem can leave the entire agent exposed.
Scenario 1: Agents Connected to Sensitive Data
One of the most critical scenarios Microsoft highlights involves agents connected to sensitive organizational data.
Agents are often grounded in internal data sources. Sometimes intentionally. Sometimes unintentionally.
They may have access to:
- Customer transaction records
- Financial datasets
- PII
- Internal documentation
These agents are typically designed for internal use. They deliver efficiency and insight. But they also create a high-value target.
If an attacker compromises such an agent, they may gain indirect access to sensitive data that was never intended to be externally accessible.
And here’s the subtle risk:
Data exfiltration through an AI agent may look like normal agent activity.
Unlike direct database access, which is clearly logged and monitored, agent-based data flows can blend into legitimate usage patterns. That makes detection significantly harder.
Microsoft Defender addresses this by providing visibility into agents connected to sensitive data and by mapping potential attack paths.
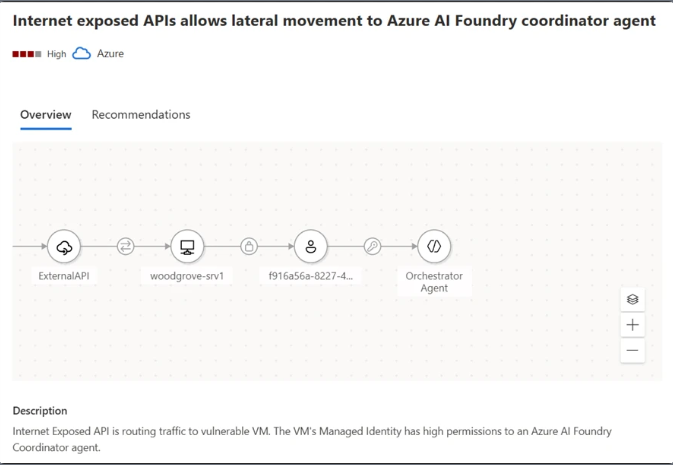
In the example Microsoft presents, an attack path demonstrates how an attacker could exploit an internet-exposed API to reach an AI agent grounded in sensitive data. Defender highlights:
- The exposure point (e.g., public API)
- The agent involved
- The sensitive data source (such as a blob container)
- The remediation steps required to close the gap
This is posture in action.
It’s not just detecting an attack.
It’s identifying the architectural risk before it becomes an incident.
Scenario 2: Identifying Agents with Indirect Prompt Injection Risk
Another risk Microsoft highlights involves what is known as Indirect Prompt Injection (XPIA), an emerging class of AI-specific attacks.
AI agents constantly interact with external data:
- User messages
- Retrieved documents
- Webpages fetched via browser tools
- Third-party APIs
- Email content
- Data pipelines
These inputs are typically treated as trustworthy. But that assumption can be exploited.
Unlike direct prompt injection, where an attacker explicitly sends malicious instructions to a model, indirect prompt injection hides those instructions inside external content. The agent retrieves or processes that content and unknowingly executes embedded or obfuscated commands because it trusts the source and operates autonomously.
In other words, the malicious instruction doesn’t arrive as a command. It arrives disguised as data.
That subtlety is what makes XPIA dangerous.
Why XPIA Becomes Critical for High-Privilege Agents
Microsoft emphasizes that the risk becomes significantly more serious when agents operate with elevated privileges.
For example, agents that can:
- Modify databases
- Trigger workflows
- Access sensitive internal systems
- Perform actions autonomously at scale
In these cases, a single manipulated webpage, document, or API response can silently influence the agent’s behavior.
The result could be:
- Unauthorized access
- Data exfiltration
- Internal system compromise
- Workflow abuse
And because the agent believes it is processing legitimate data, the execution path may not immediately appear malicious.
This makes identifying agents susceptible to XPIA a critical security requirement.
How Microsoft Defender Addresses XPIA Risk
According to Microsoft, Defender analyzes an agent’s tool combinations and configurations to determine exposure to indirect prompt injection.
The evaluation considers:
- What tools the agent can invoke
- What external sources it consumes
- The privileges it holds
- The potential impact of misuse
Based on this analysis, Microsoft Defender:
- Identifies agents with elevated exposure to indirect prompt injection
- Assigns a dedicated Risk Factor
- Generates tailored security recommendations
- Highlights missing guardrails
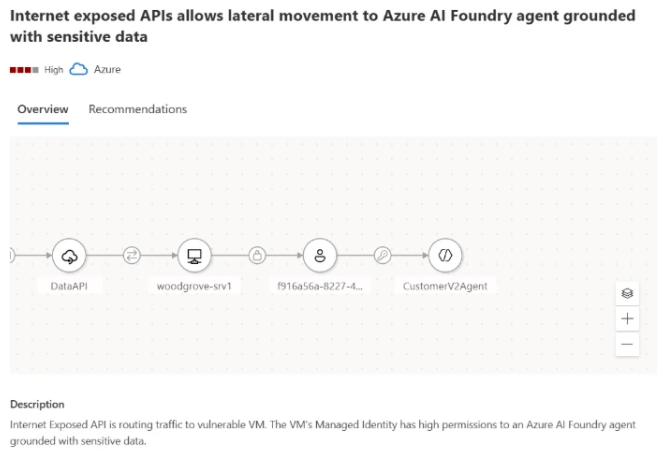
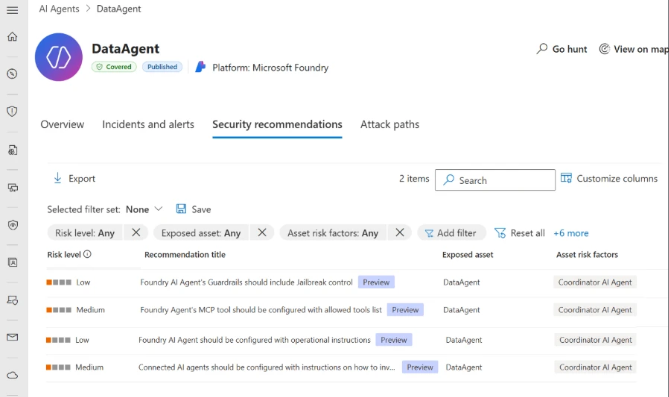
In the example Microsoft shows (Figure 2), Defender generates a recommendation for an agent exposed to indirect prompt injection risk and lacking proper guardrails.
Guardrails are essential in reducing the likelihood and impact of XPIA events. Without them, agents may blindly execute instructions embedded in external content.
This is where posture management becomes proactive.
Instead of waiting for exploitation, Defender surfaces architectural weaknesses in agent design and configuration before they are abused.

In Figure 3, we can see a recommendation generated by the Defender for an agent with both high autonomy and a high risk of indirect prompt injection, a combination that significantly increases the probability of a successful attack.
In both cases, Defender provides detailed and actionable remediation steps. For example, adding human-in-the-loop control is recommended for an agent with both high autonomy and a high indirect prompt injection risk, helping reduce the potential impact of XPIA-driven actions.
Scenario 3: Identifying Coordinator Agents
In a multi-agent architecture, not all agents carry the same level of risk. Some are narrow and task-specific. Others operate as coordinator agents, managing and directing multiple sub-agents across the system. These coordinator agents effectively act as command centers.
If a sub-agent is compromised, the impact may be limited. If a coordinator agent is compromised, the effect cascades across every sub-agent it controls. The blast radius increases dramatically. In some architectures, coordinators may also be customer-facing, which further amplifies their exposure. This combination of broad authority, system-wide influence, and external interaction makes coordinator agents especially attractive targets for attackers. Comprehensive visibility and dedicated security controls are therefore essential for their safe operation.
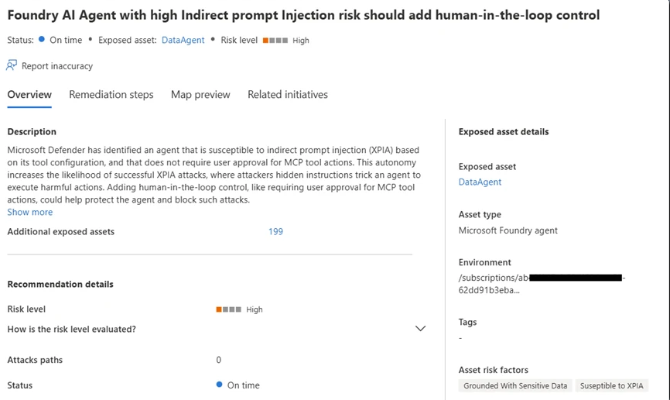
Microsoft Defender accounts for the role each agent plays within a multi-agent architecture. It provides visibility into coordinator agents and applies dedicated security insights based on their elevated impact. Defender also leverages attack path analysis to map how agent-related weaknesses can form exploitable chains. Rather than looking at agents in isolation, it connects misconfigurations, exposure points, and privilege levels into a contextual attack path.
For example, as illustrated in Figure 4, an attack path may show how an attacker could leverage an internet-exposed API to reach an Azure AI Foundry coordinator agent. This visualization enables security teams to understand not only that a risk exists, but how it could realistically be exploited, and what actions are required to break the path. This is posture applied to multi-agent systems: understanding role, impact, and interconnected exposure before an attacker does.
Hardening AI agents: reducing the attack surface
Beyond addressing individual risk scenarios, Microsoft Defender offers broad, foundational hardening guidance designed to reduce the overall attack surface of any AI agent. In addition, a new set of dedicated agents like Risk Factors further helps teams prioritize which weaknesses to mitigate first, ensuring the right issues receive the right level of attention.
Together, these controls significantly limit the blast radius of any attempted compromise. Even if an attacker identifies a manipulation path, a properly hardened and well-configured agent will prevent escalation.
By adopting Defender’s general security guidance, organizations can build AI agents that are not only capable and efficient, but resilient against both known and emerging attack techniques.
Build AI agents security from the ground up
To address these challenges across the different AI Agents layers, Microsoft Defender provides a suite of security tools tailored for AI workloads. By enabling AI Security Posture Management (AI-SPM) within the Defender for Cloud Defender CSPM plan, organizations gain comprehensive multi-cloud posture visibility and risk prioritization across platforms such as Microsoft Foundry, AWS Bedrock, and GCP Vertex AI. This multi-cloud approach ensures critical vulnerabilities and potential attack paths are effectively identified and mitigated, creating a unified and secure AI ecosystem.
Together, these integrated solutions empower enterprises to build, deploy, and operate AI technologies securely, even within a diverse and evolving threat landscape.
To learn more about Security for AI with Defender for Cloud, visit our website and documentation.

